


1 逻辑回归标准信用评分卡概述
什么是逻辑回归标准信用评分卡?类似下图这样:
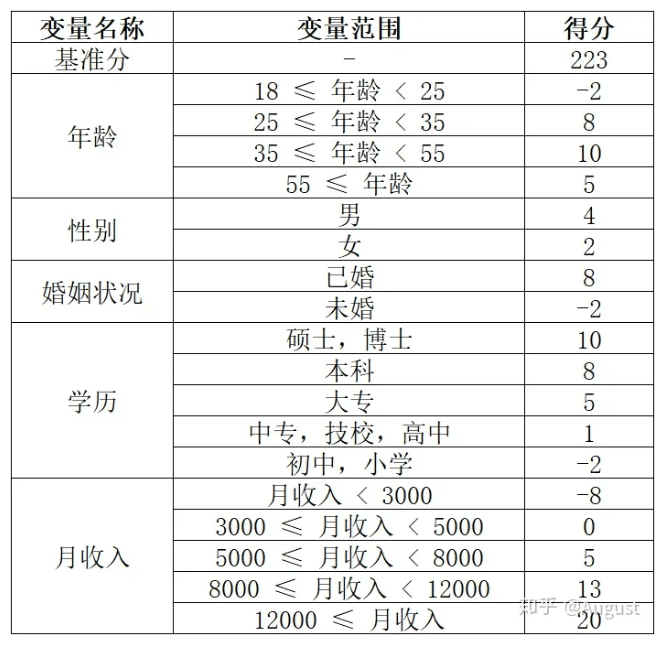
通过这个标准评分卡,我们可以方便地计算客户的信用评分,计算逻辑:
客户评分 = 基准分 + 年龄评分 + 性别评分 + 婚姻状况评分 + 学历评分 + 收入评分。
举例说明:某客户,年龄30,性别女,婚姻状况已婚,学历博士,月收入3万,那么她的信用评分:
CreditScore = 223 + 8 + 2 + 8 + 10 + 20 = 271
这样的一张标准评分卡的,有如下好处:
1)简单有效
2)方便部署和维护
3)容易理解和解释,方便与业务方沟通
如何设计和构建好,这样的一张标准评分卡,需要解决三个关键问题?
Problem1:如何从成千上百的特征集里面选择8到15个入模变量集,这就需要研究和实践特征选择算法。
Problem2:如何对变量集做分箱,这属于连续和离散变量的分箱技术。
Problem3:如何把基于逻辑回归模型预测的概率,也就是为1(坏人)的概率映射为评分点,这属于一个线性变换和处理的技术。
以上3个问题,也就对应上述标准评分卡的3列,请再次认真看下这个标准评分卡,并且告诉自己,需要解决的3个关键问题和对应的问题方向。
标准评分卡,可以在信贷流程的各个阶段发挥作用和创造价值。
1)贷前阶段,用于评估申请用户的信用,俗称为A卡。
2)贷中阶段,用于评估存量有借贷行为的客户的信用,俗称B卡。
3)贷后阶段,用于评估入催阶段客户的还款情况,俗称C卡。
2 逻辑回归标准信用评分卡设计与实现
本文,采用R语言和3个R包,提供一份逻辑回归模型标准信用评分卡的样例代码,感谢这些R包的贡献者。
代码清单工作流如下:
第一步:加载R包
第二步:加载数据和数据探索
第三步:变量粗筛选
使用数据完整性(缺失率)、特征的信用价值(IV)和特征的取值比重。
第四步:数据划分
训练集:用于训练模型
测试集:用于评价模型,测试模型的未来不可见数据的泛化性能。
第五步:变量分箱和WOE编码
1)基于条件决策树做自动化有监督变量分箱
2)针对变量分箱的可视化分析,结合领域知识,做进一步分箱的微调
第六步:设计和构建逻辑回归模型,并做共线性检测
第七步:采用特征选择算法做特征选择
1)小规模数据,可以考虑双向逐步回归
2)大规模数据,可以考虑LASSO或者变量聚类
第八步:模型性能评估
有效性指标:AUC值,ROC曲线
区分能力指标:KS值
第九步:生成标准评分卡
第十步:给客户打评分并评价评分的稳定性
使用PSI指标,度量训练集和测试集的评分稳定性
第十一步:生成决策表
结合通过率和坏账率,指导业务确定评分的切割阈值cut-off。
可以运行的参考的R样例代码:
# 查看R包帮助文档help(package= 'scorecard')
# 信用评分卡模型生成# 加载数据集data("germancredit")# 使用帮助文档查看数据集的变量含义,理解业务知识help('germancredit')# 连接到开源数据集的介绍网址# https://archive.ics.uci.edu/dataset/144/statlog+german+credit+data
# 数据理解# 发现:1000个样本,21个变量,以及每个变量的类型都可以明白germancredit %>%glimpsenames(germancredit)
# 粗筛选# 利用数据的完整性-缺失率、IV值、唯一率做筛选# 发现1个变量因为唯一率而移除# 发现6个变量因为信息价值而移除# 总共移除了7个变量dtvf <- var_filter(germancredit, "creditability")names(dtvf)# 获取移除的变量集setdiff(names(germancredit), names(dtvf))
# 数据集拆分# 训练集:用于训练模型# 测试集:用于评价模型
# 使用列表的数据集来记录两个数据集,同时单独把训练集和测试集的标签抽取和记录下来
dt_list <- split_df(dtvf, "creditability")label_list <- lapply(dt_list, function(x) x$creditability)
# Woe分箱bins <- woebin(dt_list$train, y="creditability")# 针对训练集分箱的结果做可视化分析woebin_plot(bins)# 通过这个可视化结果可以把这些图片进行保存# 然后结合业务知识进行调整和操作# 可交互式调整分箱breaks_adj <- woebin_adj(dt_list$train, "creditability", bins)
# 人工微调后,重新做分箱处理和操作breaks_adj <- list(status.of.existing.checking.account=c("... < 0 DM%,%0 <= ... < 200 DM", "... >= 200 DM / salary assignments for at least 1 year", "no checking account"), duration.in.month=c("8", "16", "26", "44"), credit.history=c("no credits taken/ all credits paid back duly%,%all credits at this bank paid back duly", "existing credits paid back duly till now%,%delay in paying off in the past", "critical account/ other credits existing (not at this bank)"), purpose=c("retraining%,%car (used)%,%radio/television", "furniture/equipment", "repairs%,%car (new)%,%business", "domestic appliances%,%education%,%others"), credit.amount=c("1000", "5000", "9600"), savings.account.and.bonds=c("... < 100 DM", "100 <= ... < 500 DM", "500 <= ... < 1000 DM%,%... >= 1000 DM%,%unknown/ no savings account"), present.employment.since=c("unemployed%,%... < 1 year", "1 <= ... < 4 years", "4 <= ... < 7 years", "... >= 7 years"), installment.rate.in.percentage.of.disposable.income=c("2", "3", "4"), other.debtors.or.guarantors=c("none%,%co-applicant", "guarantor"), property=c("real estate", "building society savings agreement/ life insurance", "car or other, not in attribute Savings account/bonds", "unknown / no property"), age.in.years=c("26", "35", "40"), other.installment.plans=c("bank%,%stores", "none"), housing=c("rent", "own", "for free"))bins_adj <- woebin(dt_list$train, y="creditability", breaks_list=breaks_adj)
# 获取各个变量的IV值信息(information value)train_df <- rbindlist(bins_adj)names(train_df)# 获取每个变量的IV值,信息价值train_df1 <- train_df %>%select(variable, total_iv) %>%distinctdim(train_df1)train_df1
# 训练集和测试集转换成woedt_woe_list <- lapply(dt_list, function(x) woebin_ply(x, bins_adj))names(dt_woe_list)
# 数据检视dt_woe_list$train %>% slice_head(n = 10) %>%View
dt_woe_list$test%>%slice_head(n = 10) %>%View
# 模型设计和构建m1 <- glm( creditability ~ ., family = binomial, data= dt_woe_list$train)# 模型结果解读summary(m1)# 自变量支架共线性关系分析# 根据gvif的值,没有出现共线性问题vif(m1, merge_coef = TRUE)
# 再次做特征选择的思路# Select a formula-based model by AIC (or by LASSO for large dataset)# 采用双向逐步回归算法m_step <- step(m1, direction="both", trace= FALSE)m2 <- eval(m_step$call)vif(m2, merge_coef = TRUE)summary(m2)# 结论:最后选择了8个入模变量集# 模型效果评价# 预测概率pred_list <- lapply(dt_woe_list, function(x) predict(m2, x, type='response'))names(pred_list)
# 模型性能分析perf <- perf_eva(pred = pred_list, label = label_list, show_plot = c('roc', 'ks'))# 获取各个对比变量的指标perf$binomial_metric
# 图形保存# 用于SCI论文的公开发表# 1)pdf格式保存ggsave("./figs/score_model_performance.pdf", plot = perf$pic, width = 7, height = 5, dpi = 300)# 2)png格式保存ggsave("./figs/score_model_performance.png", plot = perf$pic, width = 7, height = 5, dpi = 300)
# 生成标准评分卡,用于做信用评分使用card <- scorecard(bins_adj, m2)# 把评分卡转化成数据框结构card_table <- rbindlist(card, fill = TRUE)card_table %>% Viewcard_table_points <- card_table %>%select(variable, bin, points)card_table_points %>% View
# 数据集做评分score_list <- lapply(dt_list, function(x) scorecard_ply(x, card))score_list
# 模型稳定性分析# 通过psi指标psi_list <- perf_psi(score = score_list, label = label_list)
# 决策表生成# 用于做决策,确定判断阈值gtbl <- gains_table(score = unlist(score_list), label = unlist(label_list))gtbl %>%View
# 参考资料:# 1 https://github.com/ShichenXie/scorecard
关键结果如下:
1)分箱变量的可视化分析,以变量Purpose为例。
想一想:这个可视化提供哪些信息?可以留言或者加我微信讨论。

2)训练集和测试集性能评价的可视化效果图

3)逻辑回归模型标准评分卡样例

3 总结
1)逻辑回归标准信用评分卡,在金融科技行业具有重大价值。
2)逻辑回归标准信用评分卡,需要解决3个关键问题,对应为特征选择、变量分箱、概率映射评分。
3)逻辑回归标准信用评分卡的思路,可以从我提出的DFMV框架来深入思考。
数据层面,可以大胆尝试所有数据皆信用。
特征层面,积极探索和实践特征衍生和特征选择技术。
模型层面,充分理解和使用逻辑回归模型
价值层面,信贷全流程的(前中后)发挥积极作用和创造价值。
关于逻辑回归标准信用评分卡,有任何问题或想法,可以扫码添加我的微信和进入到R语言群,讨论和交流。
我是谁?
我是一名数据科研工作者,R语言知识和方法传播者,喜欢用R语言解决科研工作中数据相关的各种任务,例如:数据获取,数据整理,数据可视化,数据分析,数据建模,数据报告等。我也喜欢交流和分享R语言、数据科学、科研工作、读书跑步的故事。
欢迎你添加我的微信,进入我创建的微信社群,领取我分享6本的R语言电子书籍。返回搜狐,查看更多


